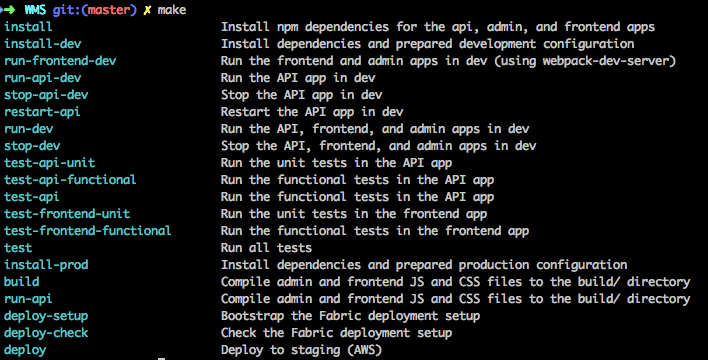
Makefiles are a venerable, reliable, and widely used technology, but wouldn’t it be
great if a Makefile could generate help about all of its targets? This post
describes a way to do not only that, but also to create an interactive
interface into your Makefile, using just fzf, ripgrep, and jq.
To avoid burying the lede, the final result looks like this:
We’re going to go into detail about the process of building out this experience, but if you want to skip ahead and see the final product, go to Tying it Back to the Makefile.
Ohterwise, read on to see how it works!
I was first keyed into the idea of a self-documenting Makefile thanks to a friend, who sent me this post from the Marmelab blog.
They describe a way to turn a Makefile with comments like this:
target: ## some descriptive comment
echo "target"
into nice help output like so:
This seemed like a really nice bit of functionality to add! Our Makefile is quite long. We try to keep it readable by documenting it well, and in fact it has almost a 1:1 ratio of comments to code.
❯ tokei ../../../gh/spec/spec-protect/Makefile
===============================================================================
Language Files Lines Code Comments Blanks
===============================================================================
Makefile 1 2050 896 893 261
===============================================================================
This is great, because you can pop open the Makefile, search for a target, and there will almost certainly be documentation for it. However, the way we’d documented our Makefile wasn’t super amenable to the method from the original post. Here’s a sample of a target with its documentation:
# See a joke from a random cow.
#
# To add cows, add them to the data/cows directory.
#
# Get the list of available cows, remove the first line (which
# shows where the cows are coming from), split the cows onto
# separate lines, remove potentially offensive cows, and then get one
# from the shuffled list.
#
# `shuf` is provided via `coreutils` in the nix environment.
#
# Then use that cow to say a joke.
#
# COWPATH will automatically be set for nix users, but if we're not in the nix
# environment, we dynamically get the base cowsay path and add our local cows to
# it.
joke: nix-dependency-check
@COWPATH=$${COWPATH:-"$$(cowsay -l | head -1 | awk '{print $$4}' | sed 's/://'):$(ROOT_DIR)/data/cows"} \
cowsay -f \
"$$(cowsay -l \
| grep -v 'Cow files in' \
| tr ' ' '\n' \
| grep '.' \
| grep -ve '\(sodomized\|telebears\|head-in\|kiss\|bong\)' \
| shuf -n 1)" \
"$$(curl -s https://icanhazdadjoke.com/)"
.PHONY: joke
This is a real target in our Makefile, and it does what it says, printing a
random dad joke via cowsay with a randomly selected cow (with some potentially
offensive cows shipped with cowsay removed from the selection). As you can see,
we’ve already got a decent one-line summary, which in the original post we’d put
after the ## on the same line as the target, but given the docstring-style way
we’ve commented our targets, it would be weird for that to follow the longer
description. In addition, some of our targets have quite a few prerequisites, so
adding a comment on the same line would make for awkwardly long lines, like so:
default: .git/hooks/pre-commit .env .nginx/tmp | .make .log docker_builds ## set up githooks, dotenv, and local directories
Of course we could split this like below, which Make would be fine with, but
multiple target: lines tend to be a bit confusing when people are new to Make.
It would also make for more difficult parsing: what happens if you wind up with
the same target on two lines, with both instances having doc-comments? On top
of that, the summary would still be below the rest of our documentation.
default: ## set up githooks, dotenv, and local directories
default: .git/hooks/pre-commit .env .nginx/tmp | .make .log docker_builds
I naturally wondered if it might be possible to use our already-existing documentation without alteration and potentially provide an interface to get even more information than the one-line summary, using the extended description for any targets where we had it.
Ultimately, we were able to combine three of my favorite command-line tools, ripgrep, jq, and fzf (along with Make of course!), to get even better results than I anticipated.
Step One: Finding the Pattern (ripgrep)
To do anything, we had to first be able to pull out the combination of “docs +
target” for each target in the Makefile. I thought about using awk for this,
tracking state when entering comments and leaving them, and building up an
associative array mapping targets to their comments. This seemed like
potentially a bit of work, and so I naturally wondered if I might be able to
just get by with the the classic everything-looks-like-a-nail text parsing tool:
regular expressions.
ripgrep supports regular expressions and is consistently one of the fastest
grep implementations in any benchmarks. It powers the search functionality in
VSCode, and it is the default search backend for many newer emacs search
utilities as well. It’s also a powerful commandline tool in its own right. It
has a couple of lesser-used features that came in super handy here. The first is
multiline regular expressions using the --multiline or -U option, described
as so in the man page:
-U, --multiline
Enable matching across multiple lines.
When multiline mode is enabled, ripgrep will lift the restriction
that a match cannot include a line terminator. For example, when
multiline mode is not enabled (the default), then the regex \p{any}
will match any Unicode codepoint other than \n. Similarly, the
regex \n is explicitly forbidden, and if you try to use it, ripgrep
will return an error. However, when multiline mode is enabled,
\p{any} will match any Unicode codepoint, including \n, and regexes
like \n are permitted.
This lets us construct a regular expression to match “at least one comment line, followed by a target definition”:
(?:^#.*\n)+[A-Za-z0-9-_./]+:
We create a non-capturing group ((?:)) of the beginning of the line (^),
followed by a literal octothorpe (#), followed by zero or more characters
(.*), followed by a literal newline (\n). We then specify that we want at
least one of (+) those groups. This whole group must then be followed by at
least one character from the set of ASCII letters and numbers, dashes,
underscores, periods, and slashes, and that must be followed by a colon (i.e. a
Make target identifier). Hopefully you can see how this would correspond to our
example target!
# See a joke from a random cow. -- matches ^#.*\n
# -- matches ^#.*\n
# To add cows, add them to the data/cows directory. -- matches ^#.*\n
# -- matches ^#.*\n
# Get the list of available cows, remove the first line (which -- matches ^#.*\n
# shows where the cows are coming from), split the cows onto -- matches ^#.*\n
# separate lines, remove potentially offensive cows, and then get one -- matches ^#.*\n
# from the shuffled list. -- matches ^#.*\n
# -- matches ^#.*\n
# `shuf` is provided via `coreutils` in the nix environment. -- matches ^#.*\n
# -- matches ^#.*\n
# Then use that cow to say a joke. -- matches ^#.*\n
# -- matches ^#.*\n
# COWPATH will automatically be set for nix users, but if we're not in the nix -- matches ^#.*\n
# environment, we dynamically get the base cowsay path and add our local cows to -- matches ^#.*\n
# it. -- matches ^#.*\n
joke: nix-dependency-check -- matches [A-Za-z0-9-_./]+:
<recipe omitted>
.PHONY: joke
I verified that this regular expression matched what I intended it to match, and so the next step was figuring out how to parse it into something usable! Ideally I wanted to be able to access the summary line, the longer description, and the target independently, so they could be combined in various ways. Also, not every target has a longer description, so it was important for crafting output to be able to handle that case.
The first difficulty though comes just with parsing the output! A multiline
regex naturally matches and outputs multiple lines, so finding the boundaries
can be tough. Luckily, ripgrep has another option to help us: --json. Again,
from the man page:
--json
Enable printing results in a JSON Lines format.
When this flag is provided, ripgrep will emit a sequence of
messages, each encoded as a JSON object, where there are five
different message types:
begin - A message that indicates a file is being searched and
contains at least one match.
end - A message the indicates a file is done being searched. This
message also include summary statistics about the search for a
particular file.
match - A message that indicates a match was found. This includes
the text and offsets of the match.
context - A message that indicates a contextual line was found.
This includes the text of the line, along with any match
information if the search was inverted.
summary - The final message emitted by ripgrep that contains
summary statistics about the search across all files.
JSON output makes me immediately think of the greatest little commandline JSON parser, jq, so let’s look at how we can parse that output!
Step Two: Parsing the Output (jq)
The JSON output from our ripgrep command to find comments and their associated
targets is a series of objects. We’re interested in the match objects, which
look like this (again for the joke target):
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile | jq
{
"type": "match",
"data": {
"path": {
"text": "Makefile"
},
"lines": {
"text": "# See a joke from a random cow.\n#\n# To add cows, add them to the data/cows directory.\n#\n# Get the list of available cows, remove the first line (which\n# shows where the cows are coming from), split the cows onto\n# separate lines, remove potentially offensive cows, and then get one\n# from the shuffled list.\n#\n# `shuf` is provided via `coreutils` in the nix environment.\n#\n# Then use that cow to say a joke.\n#\n# COWPATH will automatically be set for nix users, but if we're not in the nix\n# environment, we dynamically get the base cowsay path and add our local cows to\n# it.\njoke: nix-dependency-check\n"
},
"line_number": 2020,
"absolute_offset": 76963,
"submatches": [
{
"match": {
"text": "# See a joke from a random cow.\n#\n# To add cows, add them to the data/cows directory.\n#\n# Get the list of available cows, remove the first line (which\n# shows where the cows are coming from), split the cows onto\n# separate lines, remove potentially offensive cows, and then get one\n# from the shuffled list.\n#\n# `shuf` is provided via `coreutils` in the nix environment.\n#\n# Then use that cow to say a joke.\n#\n# COWPATH will automatically be set for nix users, but if we're not in the nix\n# environment, we dynamically get the base cowsay path and add our local cows to\n# it.\njoke:"
},
"start": 0,
"end": 581
}
]
}
}
The difference between data.lines and data.submatches.[].text is that the
latter is just the text that matched the regex, while the former is the entire
line. The fact that we can get our match alone will simplify our parsing a
little bit, since we can know for sure that the last line is just the target
name followed by the colon and doesn’t include any of the prerequisites for the
target.
jq works by applying a series of filters to incoming JSON in
order to build up a final object. Within a filter, . refers to the input data.
Objects’ properties can be accessed with dot notation, e.g.
.property.nested_property. A filter can be applied to all members of an array
with the map() filter. That’s basically all you need to know to get started,
so, let’s start parsing our output!
The first thing we need is to turn the whole thing into an array, so that we can
more easily operate on it and filter it. To do this we use the assign-update
operator, |=, with the special variable inputs, which refers to the
one-by-one data being input into jq:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile | jq '. |= [inputs]'
this yields an array of json objects like:
[
{
type: "match",
// etc...
},
// etc...
];
From this, we want to grab anywhere we’ve got match text, and then filter out
anywhere the match text was null, which gets rid of anything that’s not of the
match type. This gets us an array of strings, where each string is the matched
text from our call to ripgrep:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))'
[
"# See a joke from a random cow.\n#\n# To add cows, add them to the data/cows directory.\n#\n# Get the list of available cows, remove the first line (which\n# shows where the cows are coming from), split the cows onto\n# separate lines, remove potentially offensive cows, and then get one\n# from the shuffled list.\n#\n# `shuf` is provided via `coreutils` in the nix environment.\n#\n# Then use that cow to say a joke.\n#\n# COWPATH will automatically be set for nix users, but if we're not in the nix\n# environment, we dynamically get the base cowsay path and add our local cows to\n# it.\njoke:"
]
Great! Now we have each match as its own string in an array, so we can easily iterate over or operate on all of them. Our next job is to parse the matched text into a summary, a description, and a target. I found it easiest to do this in two steps, first splitting the target from the rest of the text, and then splitting the non-target text in twain. Regardless, we’ll have an easier time if we first split the input into an array of lines:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))'
[
[
"# See a joke from a random cow.",
"#",
"# To add cows, add them to the data/cows directory.",
"#",
"# Get the list of available cows, remove the first line (which",
"# shows where the cows are coming from), split the cows onto",
"# separate lines, remove potentially offensive cows, and then get one",
"# from the shuffled list.",
"#",
"# `shuf` is provided via `coreutils` in the nix environment.",
"#",
"# Then use that cow to say a joke.",
"#",
"# COWPATH will automatically be set for nix users, but if we're not in the nix",
"# environment, we dynamically get the base cowsay path and add our local cows to",
"# it.",
"joke:"
]
]
So our “help text” is everything but the last item of the array, while our target is the last item of the array. We can easily build this into an intermediate object like so:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})'
[
{
"help": [
"# See a joke from a random cow.",
"#",
"# To add cows, add them to the data/cows directory.",
"#",
"# Get the list of available cows, remove the first line (which",
"# shows where the cows are coming from), split the cows onto",
"# separate lines, remove potentially offensive cows, and then get one",
"# from the shuffled list.",
"#",
"# `shuf` is provided via `coreutils` in the nix environment.",
"#",
"# Then use that cow to say a joke.",
"#",
"# COWPATH will automatically be set for nix users, but if we're not in the nix",
"# environment, we dynamically get the base cowsay path and add our local cows to",
"# it."
],
"name": "joke:"
}
]
Let’s clean up the help text to remove the leading comment characters:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})'
[
{
"help": [
" See a joke from a random cow.",
"",
" To add cows, add them to the data/cows directory.",
"",
" Get the list of available cows, remove the first line (which",
" shows where the cows are coming from), split the cows onto",
" separate lines, remove potentially offensive cows, and then get one",
" from the shuffled list.",
"",
" `shuf` is provided via `coreutils` in the nix environment.",
"",
" Then use that cow to say a joke.",
"",
" COWPATH will automatically be set for nix users, but if we're not in the nix",
" environment, we dynamically get the base cowsay path and add our local cows to",
" it."
],
"name": "joke:"
}
]
And let’s remove the : from the target name:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})'
[
{
"help": [
" See a joke from a random cow.",
"",
" To add cows, add them to the data/cows directory.",
"",
" Get the list of available cows, remove the first line (which",
" shows where the cows are coming from), split the cows onto",
" separate lines, remove potentially offensive cows, and then get one",
" from the shuffled list.",
"",
" `shuf` is provided via `coreutils` in the nix environment.",
"",
" Then use that cow to say a joke.",
"",
" COWPATH will automatically be set for nix users, but if we're not in the nix",
" environment, we dynamically get the base cowsay path and add our local cows to",
" it."
],
"name": "joke"
}
]
At this point, we’ve got enough information to filter out some targets. For
example, we chose not to include targets whose names started with a period
(.), since these are in practice generally not targets that our engineers need
to call directly:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))'
And now we’re ready to build up our final object, splitting the help text into a summary and then a description:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})'
[
{
"summary": " See a joke from a random cow.",
"description": [
"",
" To add cows, add them to the data/cows directory.",
"",
" Get the list of available cows, remove the first line (which",
" shows where the cows are coming from), split the cows onto",
" separate lines, remove potentially offensive cows, and then get one",
" from the shuffled list.",
"",
" `shuf` is provided via `coreutils` in the nix environment.",
"",
" Then use that cow to say a joke.",
"",
" COWPATH will automatically be set for nix users, but if we're not in the nix",
" environment, we dynamically get the base cowsay path and add our local cows to",
" it."
],
"name": "joke"
}
]
Of course we now have a new problem! The long descriptions often wind up with an extra blank line at the front. The following filters can be used to remove leading and trailing whitespace, essentially telling jq to build a new array by iterating over the existing one, and while the first or last item is the empty string, returning the rest of the array with that item excluded (don’t worry, this is the most complicated filter by far).
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})'
[
{
"summary": " See a joke from a random cow.",
"name": "joke",
"description": [
" To add cows, add them to the data/cows directory.",
"",
" Get the list of available cows, remove the first line (which",
" shows where the cows are coming from), split the cows onto",
" separate lines, remove potentially offensive cows, and then get one",
" from the shuffled list.",
"",
" `shuf` is provided via `coreutils` in the nix environment.",
"",
" Then use that cow to say a joke.",
"",
" COWPATH will automatically be set for nix users, but if we're not in the nix",
" environment, we dynamically get the base cowsay path and add our local cows to",
" it."
]
}
]
If desired, we can also sort the output by target name:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq --raw-output '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})
| sort_by(.name)'
Phew! That was a lot, and in practice we wound up combining some of these filters for efficiency, but even as it stands, it’s not slow:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq --raw-output '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})
| sort_by(.name)'
real 0m0.125s
user 0m0.026s
sys 0m0.005s
Now that we’ve got a well-defined JSON object, we can start using it in interesting ways!
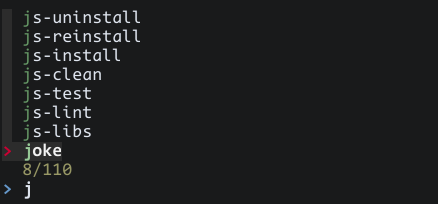
Step Three: Interactivity (fzf)
fzf is an interactive fuzzy-finder, with a huge number of features to build
rich selection experiences. Let’s start out by building a basic select for our
make targets. We’ll take all our JSON objects, filter them down to just the
target name, and join with newlines, giving us one line per target. We’ll pass
the --raw-output argument to jq so that the newlines will be rendered as such,
and then we’ll pass the result to fzf:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq --raw-output '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})
| sort_by(.name)
| map(.name)
| join("\n")' |
fzf
This gives us a simple selection interface that looks like this:
Okay, this is nice, but we want to use all the nice help data we took the time
to parse out of our Makefile. Luckily, jq lets you build up arbitrary strings,
and at any point you can add an escape sequence like \(expression) to
interpolate data from the jq filter using any valid jq expression. So, let’s
build up a string that:
- colors the target cyan
- includes the help summary
- aligns everything nicely
That last bit jq is actually not particularly good at, but our old standby awk
is great at it, so we’ll pop out to awk once we’ve accomplished the first two
goals. To color things cyan, we’ll use the standard ANSI color codes,
replacing \e in the linked codes with its unicode equivalent, \u001b,
since we’re working with UTF-8 text:
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq --raw-output '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})
| sort_by(.name)
| map("\u001b[36m\(.name)\u001b[0m\t\t\(.summary)")
| join("\n")' |
awk -F "\t\t" '{printf "%-35s %s\n", $1, $2}' |
fzf --ansi
Note in our filter that creates a string:
"\u001b[36m\(.name)\u001b[0m\t\t\(.summary)"
The first escape, \u001b[36m, turns “on” cyan, and the second \u001b[0m,
resets the color to whatever it was before. We separate the name from the
summary with two tabs, \t\t, just to have something unlikely to occur in any
of our help text to use as the field separator (the -F argument) in the call
to awk. The awk command says to print the first and second fields ($1 and
$2, respectively), with the first field padded with 35 characters on the right
side via %-35s. You can adjust this padding to whatever makes sense for your
data. Note also that in order to display the color, rather than just
displaying the escape codes, we have to pass the --ansi argument to fzf.
With this, we’ve now got a pretty nice interactive select for a make target. It looks like this:

However, we can make this even better with the very cool preview functionality that fzf provides.
Taking It Further: Interactive Previews
We’re in a pretty good place now. We’re able to present a nice interactive view
of our Makefile targets, but we’ve still got all that extra descriptive help
text that we’re not using, and what if we could provide even more useful,
contextual information to the caller of make to help them understand what
they’re about to do?
One of the arguments to the fzf binary is --preview. The docs on this are
honestly a bit rough in my opinion, but here’s the relevant bit of the man page
in its entirety, just so that you too can attempt to wade through it like I did:
Preview
--preview=COMMAND
Execute the given command for the current line and display the
result on the preview window. {} in the command is the place‐
holder that is replaced to the single-quoted string of the cur‐
rent line. To transform the replacement string, specify field
index expressions between the braces (See FIELD INDEX EXPRESSION
for the details).
e.g.
fzf --preview='head -$LINES {}'
ls -l | fzf --preview="echo user={3} when={-4..-2}; cat
{-1}" --header-lines=1
fzf exports $FZF_PREVIEW_LINES and $FZF_PREVIEW_COLUMNS so that
they represent the exact size of the preview window. (It also
overrides $LINES and $COLUMNS with the same values but they can
be reset by the default shell, so prefer to refer to the ones
with FZF_PREVIEW_ prefix.)
A placeholder expression starting with + flag will be replaced
to the space-separated list of the selected lines (or the cur‐
rent line if no selection was made) individually quoted.
e.g.
fzf --multi --preview='head -10 {+}'
git log --oneline | fzf --multi --preview 'git show {+1}'
When using a field index expression, leading and trailing white‐
space is stripped from the replacement string. To preserve the
whitespace, use the s flag.
Also, {q} is replaced to the current query string, and {n} is
replaced to zero-based ordinal index of the line. Use {+n} if
you want all index numbers when multiple lines are selected.
A placeholder expression with f flag is replaced to the path of
a temporary file that holds the evaluated list. This is useful
when you multi-select a large number of items and the length of
the evaluated string may exceed ARG_MAX.
e.g.
# Press CTRL-A to select 100K items and see the sum of all
the numbers.
# This won't work properly without 'f' flag due to ARG_MAX
limit.
seq 100000 | fzf --multi --bind ctrl-a:select-all \
--preview "awk '{sum+=} END {print sum}'
{+f}"
Note that you can escape a placeholder pattern by prepending a
backslash.
Preview window will be updated even when there is no match for
the current query if any of the placeholder expressions evalu‐
ates to a non-empty string.
Since 0.24.0, fzf can render partial preview content before the
preview command completes. ANSI escape sequence for clearing the
display (CSI 2 J) is supported, so you can use it to implement
preview window that is constantly updating.
e.g.
fzf --preview 'for i in $(seq 100000); do
(( i % 200 == 0 )) && printf "\033[2J"
echo "$i"
sleep 0.01
done'
The important thing is, we can essentially pass --preview an arbitrary
command, which it will run for whatever the currently selected candidate is, and
the output of that command will populate a preview window in the search results.
There are a couple of key things to take away from the docs:
{}in the command is replaced with the current candidate- A “field index expression” refers to which “field” of the input to use. You
can specify the field separator, but fzf by default uses a similar heuristic
to awk to determine fields, splitting on whitespace. You can use a field from
the input by saying e.g.
{1}to use the first field, instead of{}to use all the input.
Okay so in theory we can pass our whole big jq filtration into the --preview
command, get the long description, and use that as the preview, right? We’d
ideally want to do the main chunk of the work once, save it in a variable, and
pass it into a new JQ filter in the preview command. Something like this:
# DOES NOT WORK!!!
JSON_DATA=$(
rg --multiline --json '(?:#.*\n)+[A-Za-z0-9-_./]+:' Makefile |
jq --raw-output '. |= [inputs]
| map(.data.submatches[0].match.text)
| map(select(. != null))
| map(split("\n"))
| map({help: .[0:-1], name: .[-1]})
| map({help: .help | map(ltrimstr("#")) | map(ltrimstr("#")), name: .name})
| map({help: .help, name: .name | rtrimstr(":")})
| map(select(.name | startswith(".") | not))
| map({summary: .help[0], description: .help[1:], name: .name})
| map({summary: .summary, name: .name, description: .description | until(.[0] != ""; .[1:]) | until(.[-1] != ""; .[:-1])})
| sort_by(.name)'
)
export JSON_DATA=$JSON_DATA
echo "$JSON_DATA" | jq --raw-output \
'map("\u001b[36m\(.name)\u001b[0m\t\t\(.summary)")
| join("\n")' |
awk -F "\t\t" '{printf "%-35s %s\n", $1, $2}' |
fzf --ansi --preview-window bottom --preview 'echo $JSON_DATA | jq'
But we wind up with terribly obtuse errors in our preview output like:
[
/bin/bash: -c: line 819: syntax error: unexpected end of file
The problem is the intricate and arcane art of shell quoting. We’re trying to
create a string for fzf to run as a command, but our string contains newlines
and double quotes that we want to pass into jq. This is just a hard problem.
One option to make it easier is to export our data as an environment variable,
and use that in jq instead, so something like this:
export JSON_DATA=$JSON_DATA
echo "$JSON_DATA" | jq --raw-output \
'map("\u001b[36m\(.name)\u001b[0m\t\t\(.summary)")
| join("\n")' |
awk -F "\t\t" '{printf "%-35s %s\n", $1, $2}' |
fzf \
--ansi \
--preview-window bottom \
--preview 'echo $JSON_DATA \
| jq --raw-output '"'"'map(select(.name == "{1}"))
| .[0].description
| join("\n")'"'"''
Note the use of the insane '"'"' to escape a single quote within a
single-quoted string, which essentially ends the single-quoted string and
concats it to a double-quoted string containing only a single-quote, which is
then concatted with the remainder of the single-quoted string.
But hey, this gets us pretty much what we want!
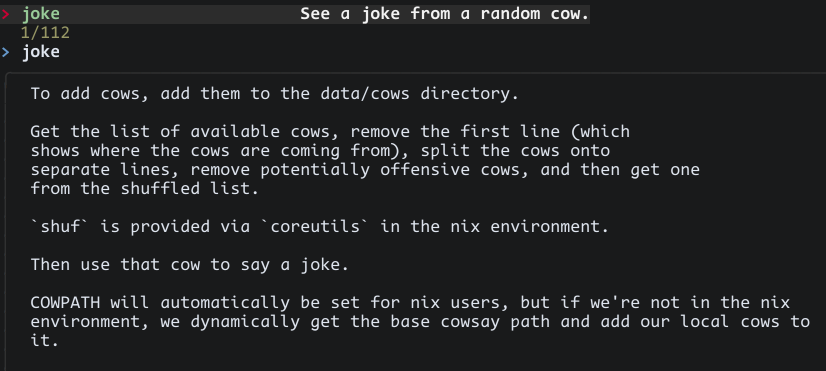
However, it’s got readability problems, and it’s far from reusable. A much easier alternative is to separate the filtration into helper script.
We’ve published our helper script under the MIT license, and you can find it
here. It should be pretty much usable out-of-the-box. You may
just need to change the ROOT_DIR variable to point to your project’s root
relative to where you store the script, and you may want to update the COLORS
object to contain more than cyan.
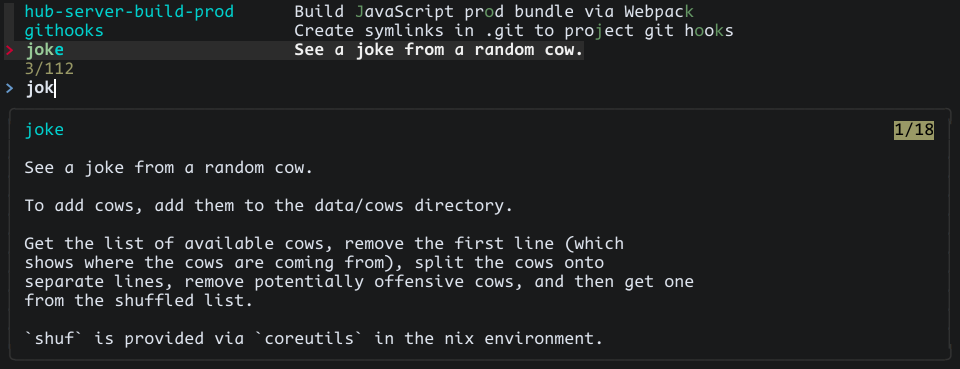
With our script in place, we can now do this:
# The jq filter for use for preview window content
preview_filter='"\(colors.cyan)\(.name)\(colors.reset)\n\n\(.summary)\n\n\(.description | join("\n"))"'
# This is the command fzf will run for each target to generate a preview. The
# {1} refers to the first field of the fzf input, which will be the currently
# selected target. We pass that into our script to get the help detail for the
# target, applying the filter above for formatting.
preview_cmd="./scripts/dev/parse-make-help.sh \
--target {1} \
--filter '$preview_filter' \
--filter-args '-r'"
# Call our helpers script, getting all targets' output and applying a display
# filter for the summary data.
./scripts/parse-make-help.sh \
--filter 'map("\(colors.cyan)\(.name)\(colors.reset)\t\t\(.summary)") | join("\n")' \
--filter-args '--raw-output' \
| awk -F "\t\t" '{printf "%-35s %s\n", $1, $2}' \
| fzf \
--ansi \
--preview "$preview_cmd" \
--preview-window="bottom"
This makes it easy to iterate on our preview filter, and we wind up with something like this:
For fun, we can extend our previews even more and include the “dry-run” output
for the Make target, which will show which commands will be run, if any. This is
as easy as extending the preview_cmd variable above to be:
preview_cmd="./scripts/dev/parse-make-help.sh \
--target {1} \
--filter '$preview_filter' \
--filter-args '-r';
echo '';
echo 'Dry run for make {1}'
echo '-----'
make --dry-run {1}"
Running the Selected Make Command
Okay so we’ve got a nice preview, but it would be even nicer if you could just press Enter on your selected target and be off to the races. Like most nice things, it’s possible with a little effort.
What we need to do is:
- Output the text selected with
fzf - Parse the target back out of the selected text
- Call
makewith the target
Step one is exactly what fzf does by default, and parsing the target out is
easy peasy with awk. This gives us something like:
# Assuming the same preview_filter and preview_cmd variables as in the
# examples above
# We just take our same commmand and then pipe it to awk to get the target,
# assigning that target to a variable
make_cmd=$(
./scripts/parse-make-help.sh \
--filter 'map("\(colors.cyan)\(.name)\(colors.reset)\t\t\(.summary)") | join("\n")' \
--filter-args '--raw-output' \
| awk -F "\t\t" '{printf "%-35s %s\n", $1, $2}' \
| fzf \
--ansi \
--preview "$preview_cmd" \
--preview-window="bottom" |
| awk '{print $1}'
)
# Then we call make, first outputting what we're doing so it's more obvious than
# if all sorts of make text just starts spitting out
echo "make $make_cmd"
make "$make_cmd"
This is not super useful on its own in the shell, but will be key for ergonomic usage via a Makefile target.
Tying It Back to the Makefile
Now we’re ready to accomplish our end goal! If you don’t already have an
important default target (the first target in the Makefile, which is run
whenever you run make with no arguments), you can set this up as the default
target. Otherwise, it can be selected like any other target.
Before presenting the target, just to recap, at this point we’ve got our
helper script installed somewhere in our repo to handle all of
our complex filtering needs. This target assumes the script is in a scripts/
directory next to the Makefile, but of course you can put it wherever you like
and adjust the target.
With that out of the way, here’s a Make target that:
- Provide a fuzzy selection interface of commands with their one-line summaries
- When a command is selected, show its detailed help text in a preview window, along with a dry-run of what the make command will do when executed
- Runs the selected Make command when selected
Please note that the helper script assumes a relatively modern bash, so if
you’re on a Mac, you may need to brew install bash or similar to get something
less than a decade out of date.
Please also note that Make requires tabs for indentation (not spaces). The snippet below should contain tabs, but these may or may not be retained when copying and pasting into your editor, so double check if you get errors.
# Select a make target interactively
#
# Presents an interactive interface where the user can fuzzy match a make target,
# matching on the target itself or the target's docstring. The full help of the
# currently selected target is shown, along with a dry-run of the commands that
# would be executed if it were selected.
select:
@# Filter to convert name, summary, and description to strings for all targets
# and join with newlines.
preview_filter='"\(colors.cyan)\(.name)\(colors.reset)\n\n\(.summary)\n\n\(.description | join("\n"))"'
# Preview is output of the above filter, then the dry run for the target,
# which will show what commands it would run
preview_cmd="./scripts/parse-make-help.sh \
--target {1} \
--filter '$$preview_filter' \
--filter-args '-r';
echo '';
echo 'Dry Run for make {1}'
echo '-----'
$(RUN_MAKE) --dry-run {1}"
# fzf input is each parsed target's name and summary on one line, with all
# targets joined w/newlines. Each line is passed to awk for alignment.
MAKE_CMD=$$(
./scripts/parse-make-help.sh \
--filter 'map("\(colors.cyan)\(.name)\(colors.reset)\t\t\(.summary)") | join("\n")' \
--filter-args '-r' |
awk -F "\t\t" '{printf "%-35s %s\n", $$1, $$2}' |
fzf \
--ansi \
--preview="$$preview_cmd" \
--preview-window="bottom" |
awk '{print $$1}'
)
# Make it obvious what was selected, and then run it.
echo "make $$MAKE_CMD"
# Ensure we're using the correct Makefile in case we're invoked via recursive Make
$(MAKE) -f $(MAKEFILE) --no-print-directory $$MAKE_CMD
# This is a PHONY target, because it doesn't produce a file as output, and we
# want it to run every time it's invoked.
.PHONY: select
Again, this gets us this very nice target selection experience, which you can
access either by running make select or, if it’s the first target in your
Makefile, just make:
Even More Targets
Because all of our parsing is controlled by our helper script, and we can easily
customize its output, we can use the same approach to make a simpler help
target, that just prints out all of the targets and their one-line summaries:
# Print make targets along with their summaries
help:
@jq_filter='map("\(colors.cyan)\(.name)\(colors.reset)\n \(.summary)") | join("\n\n")'
./scripts/dev/parse-make-help.sh --filter="$$jq_filter" --filter-args='-r'
echo ''
echo "To see extended help, use 'make help-long'"
.PHONY: help
Or a more complex help-long that prints summaries and descriptions:
# Print make targets, their summaries, and their extended descriptions
help-long:
@jq_filter='map('
jq_filter+='"\(colors.cyan)\(.name)\(colors.reset)\n'
jq_filter+=' \(.summary)'
jq_filter+='\(if .description != [] then "\n\n " + (.description | join("\n ")) else "" end)"'
jq_filter+=') | join("\n\n")'
./scripts/dev/parse-make-help.sh --filter="$$jq_filter" --filter-args='-r'
.PHONY: help-long
Since you can pass any filter you want, you can format the parsed data however you like for any number of other interesting targets!
That’s it for today, and we hope you find this helpful! If you’d like to chat or have any ideas for improvements, please feel free to drop us a line at engineering@spec-trust.com.